3.《CNI および CNI プラグインについて》
はじめに:ネットワークアーキテクチャは、K8sの複雑な箇所の1つです。 K8sネットワークモデル自体には、それぞれのネットワーク機能に対するそれぞれの要求があるため、業界にはすでに特定の環境と要求を満たすための多くのネットワークソリューションがあります。CNIは、コンテナが作成または破棄されたときにユーザーがコンテナネットワークをより簡単に構成できるようにするためのコンテナネットワークのAPIインターフェースを意味します。この記事では、一般的なネットワークプラグインの動作原理を理解し、CNIプラグインの使用方法を習得するための方法を説明します。
CNI とは何か
最初に、CNIとは何かを紹介しましょう。その正式名称は、Container Network Interface、つまりコンテナネットワークのAPIインターフェースです。
それはK8sに標準に実装されたネットワークインターフェースです。 Kubeletはこの標準APIを使用して、さまざまなネットワークプラグインを呼び出し、さまざまなネットワーク構成メソッドを実現します。このインターフェースを実装するのは、一連のCNI APIインターフェースを実装するCNIプラグインです。 一般的なCNIプラグインには、Calico、flannel、Terway、Weave Net、およびContivが含まれます。
Kubernetes でCNIを使用する方法
K8sはCNI構成ファイルにより、使用するCNIを決定します。
基本的な使用方法は次のとおりです。
- 最初に、各ノードでCNI構成ファイル(/etc/cni/net.d/xxnet.conf)を構成します。ここで、xxnet.confは特定のネットワーク構成ファイルの名前です。
- 対応するバイナリプラグインをCNI構成ファイルにインストールします。
- このノードでPodを作成した後、Kubeletは、CNI構成ファイルに従って、最初の2つのステップでインストールされたCNIプラグインを実行します。
- 上記のステップが完了すると、Podネットワーク構成が完了します。
具体的なプロセスを次の図に示します。
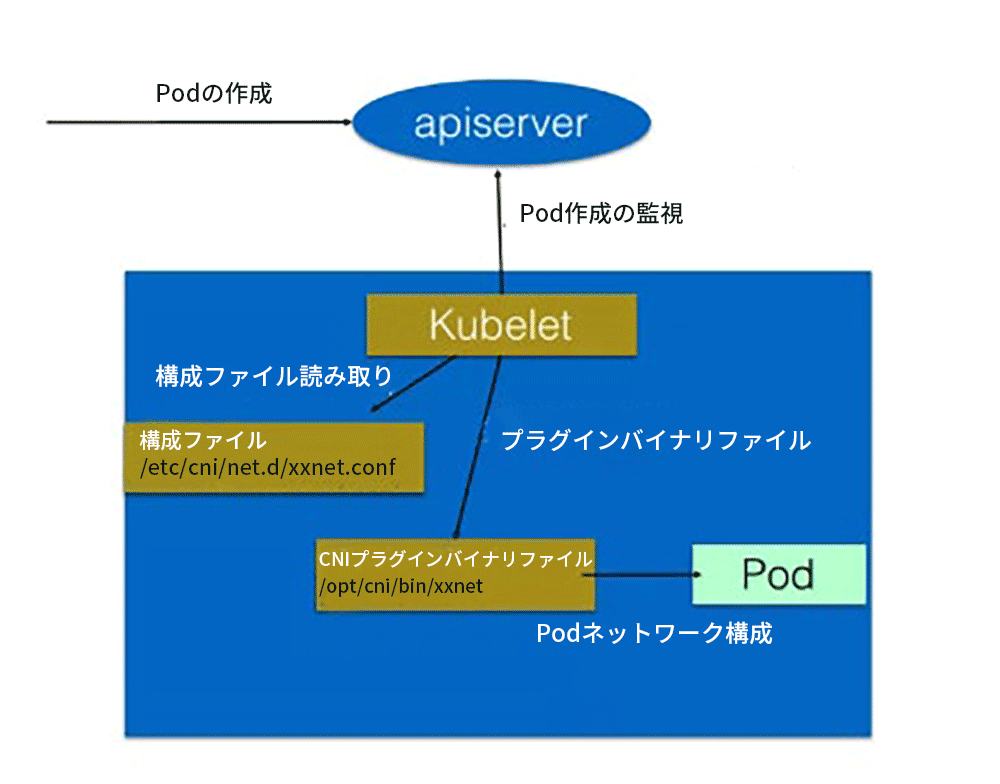
クラスターにPodを作成する場合、Pod構成は最初にapiserverを介して書き込まれます。 apiserverの一部の管理コンポーネント(スケジューラーなど)は、特定のノードにスケジュールされます。 このPodの作成を監視した後、Kubeletはローカルでいくつかの作成操作を実行します。
ネットワークを作成するステップを実行すると、最初に、前述の構成ディレクトリにある構成ファイルが読み取られます。構成ファイルは、使用するプラグインを宣言し、特定のCNIプラグインのバイナリファイルを実行します。 次に、CNIプラグインがPodネットワークスペースに入り、Podネットワークを構成します。 構成が完了すると、KuberletはPod作成プロセス全体を完了し、Podはオンラインになります。
上記のプロセスには多くのステップ(CNI構成ファイルの構成、バイナリプラグインのインストールなど)があり、すこし複雑に見えます。
しかし、ユーザーとしてCNIプラグインのみを使用する場合、多くのCNIプラグインがすでにワンクリックインストール機能を提供しているため、比較的簡単です。 次の図に示すように、一般的に使用されるFlannelを例にとります。kubectlapply Flannelのデプロイテンプレートを使用するだけで、構成ファイルとバイナリファイルを各ノードに自動的にインストールできます。
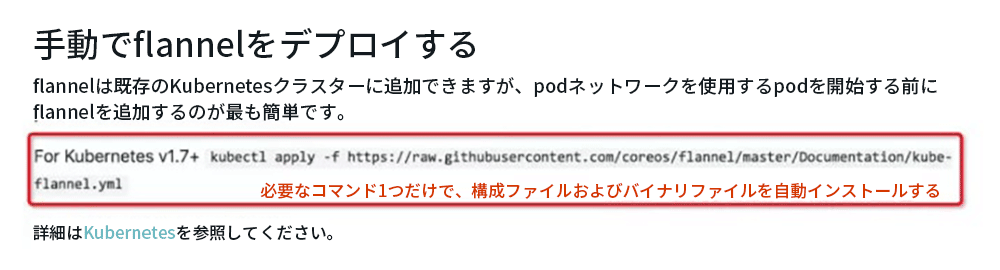
インストール後、クラスター全体のCNIプラグインがインストールされます。
したがって、CNIプラグインのみを使用する場合、多くのCNIプラグインはすでにワンクリックインストールスクリプトを提供しており、Kubernetesの内部構成方法やAPIの呼び出し方法を誰もが気にする必要はありません。
どのCNIプラグインが私達にとって適切か?
コミュニティには、Calico、flannel、Terwayなど、多くのCNIプラグインがあります。では、具体的な使用環境では、どのCNIプラグインを選択すればよいでしょうか。CNIのいくつかの実装モデルから話していきましょう。 私達はさまざまなシナリオに従ってさまざまな実装モードを選択してから、特定のプラグインを選択する必要があります。
一般的に、CNIプラグインは、オーバーレイ、ルーティング、アンダーレイの3つのモードに分類できます。
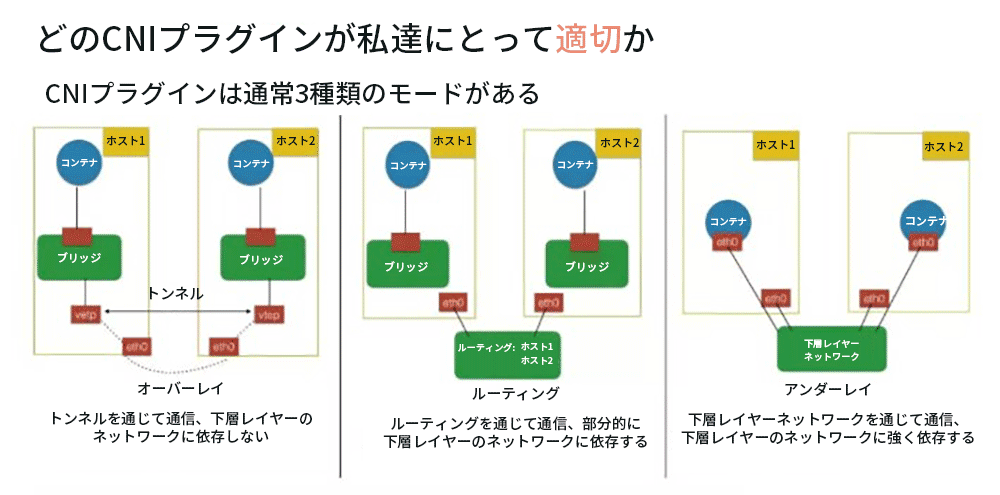
- オーバーレイモードの典型的な特徴は、コンテナがホストのIPセグメントから独立していることであり、このIPセグメントは、ホスト間にトンネルを作成することにより、ホスト間ネットワーク通信に使用されます。コンテナネットワークセグメント全体のすべてのパケットは、下層レイヤーにある物理ネットワーク内のホスト間のパケットにカプセル化されます。この方法の利点は、基盤となるネットワークに依存しないことです。
- ルーティングモードでは、ホストとコンテナは異なるネットワークセグメントに属しています。オーバーレイモードとの主な違いは、そのホスト間通信がルーティングを介して行われるため、異なるホスト間でトンネルパケットを作成する必要がないことです。ただし、ルーティングは部分的に下層にあるネットワークに依存する必要があります。たとえば、下層レイヤーにあるネットワークにはレイヤー2で到達可能性な機能が必要です。
- アンダーレイモードでは、コンテナとホストはネットワークの同じレイヤーにあり、両方とも同じステータスです。 コンテナ間のネットワーク接続は、下層レイヤーにあるネットワークに依存するため、したがって、このモデルは下層のネットワークの能力に強く依存しています。
上記の3つの一般的に使用される実装モードを理解したら、環境とニーズに応じて実装できるモードを決定し、対応するモードでCNIプラグインを見つけます。
しかし、コミュニティには非常に多くのプラグインがあります。それらはどのモデルに属しているのでしょうか? どのようにして選ぶのでしょうか? あなたに適したものを選ぶ方法は?次の3つの方面から考えることができます。
1. 環境制約
異なった環境においてサポートされる下層レイヤーの能力も異なります。
- 仮想化環境(OpenStackなど)には多くのネットワーク制約があります(たとえば、レイヤー2プロトコルを介してマシン間で直接アクセスすることは許可されていません。転送するには、レイヤー3 IPアドレスが必要です)。 IPなどを使用する、強く制約されているこの下層レイヤーのネットワークでは、オーバーレイプラグインのみを選択できます。一般的なものは、Flannel-vxlan、Calico-ipip、Weaveなどです。
- 物理マシン環境では下層レイヤーのネットワークに対する制約が少なく、たとえば、同じスイッチで直接レイヤー2通信を実行します。 このクラスター環境では、アンダーレイのプラグインまたはルーティングモードを選択できます。 アンダーレイとは、物理マシンに複数のネットワークカードを直接挿入するか、一部のネットワークカードでハードウェア仮想化を実行できることを意味します。ルーティングモードは、Linuxルーティングプロトコルに依存して通過します。これにより、vxlanなどのパケット化方式によるパフォーマンスの低下が回避されます。この環境でのオプションのプラグインには、clico-bgp、flannel-hostgw、sriovなどがあります。
- パブリッククラウド環境も仮想化されているため、下層レイヤーの制約がさらにあります。 ただし、各パブリッククラウドは、コンテナのパフォーマンスを向上させるためにコンテナを適応させることを検討するため、追加のネットワークカードやルーティング機能を構成するためのAPIを提供する場合があります。 パブリッククラウドでは、最高の互換性とパフォーマンスを実現するために、パブリッククラウドベンダーが提供するCNIプラグインを選択するために最善を尽くす必要があります。 たとえば、Aliyunは高性能のTerwayプラグインを提供します。
環境制約を考慮した後、何を使用できるか、何を使用できないかを知り、いくつかの選択肢を念頭に置く必要があります。これに基づき機能要件を考慮する必要があります。
2. 機能要件
- 第一にセキュリティ要求
K8sはNetworkPolicyをサポートしています。つまり、NetworkPolicyルールを通じて「Pod間でアクセスできるかどうか」というポリシーをサポートできます。 ただし、すべてのCNIプラグインがNetworkPolicyのステートメントをサポートしているわけではありません。この要件がある場合は、Calico、WeaveなどのNetworkPolicyのプラグインをサポートすることを選択できます。
- 2番目に、クラスター外のリソースをクラスター内のリソースと相互接続する必要があるかどうか
皆さんのアプリケーションは、最初は仮想マシンまたは物理マシン上にあります。コンテナ化後、アプリケーションは一度に移行できないため、従来の仮想マシンまたは物理マシンはコンテナのIPアドレスと通信する必要があります。この種のインターワーキングを実現するには、2者間を接続する方法、または同じレイヤーに直接配置する方法が必要です。このとき、アンダーレイネットワークを選択できます。たとえば、sriovは、Podが以前の仮想マシンまたは物理マシンと同じレイヤーにあります。 また、calico-bgpを使用することもできます。現時点では、同じネットワークセグメントに属していませんが、これを使用して、仮想マシンとコンテナを開くことができる元のルーターでBGPルートをアドバタイズできます。
- 最後に、K8sのサービス検出およびロードバランシング機能
K8のサービスディスカバリとロードバランシングは、上記に紹介したK8sのサービスですが、すべてのCNIプラグインがこれら2つの機能を実現できるわけではありません。たとえば、アンダーレイモードの多くのプラグイン、Pod内のネットワークカードはアンダーレイハードウェアによって直接使用されるか、ハードウェア仮想化を通じてコンテナーにプラグインされます。この時、そのトラフィックはホストが配置されているネームスペースに到達できません。したがって、kube-proxyによってホストに設定されたルールは適用できません。
機能要件を選別した後、選択可能なプラグインはとても少なくなります。環境制約と機能要件にて選別した後、3か4のプラグインが残っている場合は、性能要件を検討できます。
3. 性能要件
Pod作成速度とPodネットワークパフォーマンスの観点から、さまざまなプラグインのパフォーマンスを測定できます。
- Pod作成速度
ビジネスピークが来たときなど、Podのグループを作成するときは、急いで容量を拡張する必要があります。たとえば、1000のPodを拡張する場合は、CNIプラグインで1000のネットワークリソースを作成して構成する必要があります。この場合、オーバーレイモードとルーティングモードはマシン内で仮想化されるため、非常に迅速に作成されます。したがって、これらの操作を完了するには、カーネルインターフェースを呼び出すだけで済みます。 ただし、アンダーレイモードの場合、下層レイヤーのネットワークリソースを作成する必要があるため、Pod全体の作成速度は比較的遅くなります。 したがって、緊急時の容量拡張が必要な場合や、Podの大規模なバッチが作成されることが多いシナリオでは、オーバーレイまたはルーティングモードのネットワークプラグインを選択する必要があります。
- Podのネットワーク性能
Podのネットワーク性能は主に、ネットワーク転送、ネットワーク帯域幅、2つのPod間のPPS遅延などのこれらのパフォーマンスインジケーターに現れます。 オーバーレイモードは、ノードに仮想化された別のレイヤーがあり、カプセル化を解除する必要があるため、パフォーマンスが低下します。また、パケットにより、パケットヘッダーの損失、CPU消費などが発生します。ネットワークパフォーマンスの要件が高い場合、たとえば機械学習やビッグデータ等は、オーバーレイモードの使用には適していません。この場合、通常はアンダーレイまたはルーティングモードでCNIプラグインを選択します。
これらの3つのステップを通して、誰でも適切なネットワークプラグインを見つける事ができると考えます。
独自のCNIプラグインを開発する方法
コミュニティプラグインは、独自のニーズを満たすことができない場合があります。たとえば、Alibaba Cloudでは、vxlanなどのオーバーレイプラグインしか使用できず、オーバーレイプラグインのパフォーマンスは比較的低く、Alibaba Cloudの一部のビジネスニーズを満たすことができません。そこでTerwayプラグインがAlibaba Cloud上で開発されました。
自己の環境が比較的特殊で、コミュニティで適切なネットワークプラグインが見つからない場合は、独自のCNIプラグインを開発できます。
CNIプラグインの実装は通常、2つの部分で構成されています。
- PodネットワークカードとIPアドレスを構成するためのバイナリCNIプラグイン。この構成手順が完了すると、ネットワークケーブルをPodに差し込むのと同じになります。つまり、Podには独自のIPと独自のネットワークカードがあることになります。
- Daemonプロセスは、Pod間のネットワーク接続を管理します。この手順は、Podが実際にネットワークに接続されているため、Podが相互に通信できることを意味します。
1. インターネットケーブルをPodに差し込む
では、どのようにPodにインターネットケーブルに接続する最初のステップを実現するのでしょうか?通常このような一つのステップになります。
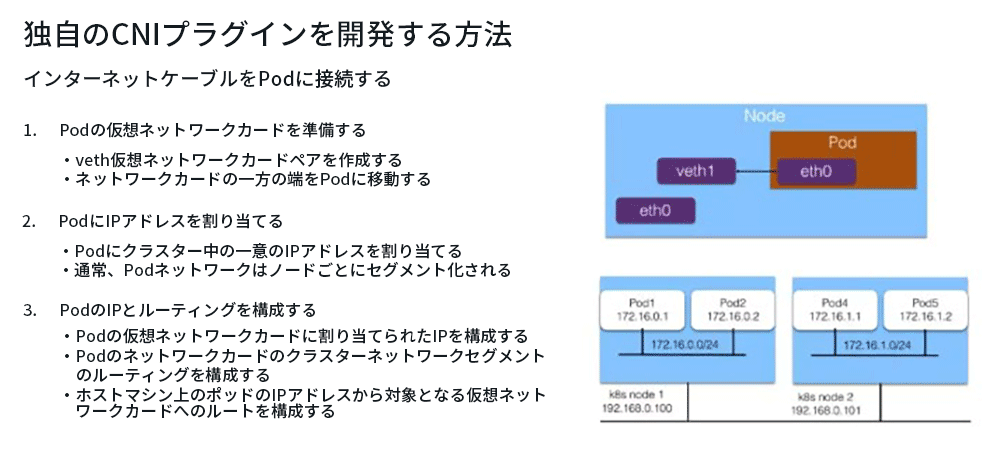
Pod用のネットワークカードを準備する
通常、「veth」仮想ネットワークカードを使用します。一方の端はPodネットワークスペースに配置され、もう一方の端はホストネットワークスペースに配置されるため、Podとホストの2つの名前空間が接続されます。
PodにIPアドレスを割り当てる
このIPアドレスには要件があり、これは以前にネットワークについて紹介したときにも言及したものです。つまり、このIPアドレスはクラスター内で一意である必要があります。 ではどうやってPodにクラスター内で一意のIPアドレスが割り当てられていることを保証すればよいでしょうか?
一般的に、クラスター全体を作成するときは、Podの大きなネットワークセグメントを指定し、各ノードに応じてノードネットワークセグメントを割り当てます。たとえば、上図の右側に172.16ネットワークセグメントを作成し、各ノードに/ 24セグメントを割り当てて、各ノードのアドレスが互いに競合しないようにします。 次に、各Podに特定のノードのネットワークセグメントから特定のIPアドレスを割り当てます。たとえば、Pod1は172.16.0.1に割り当てられ、Pod2は172.16.0.2に割り当てられます。このようにして、ノードでのIPアドレス割り当てに競合はありません。また、異なるノードは異なるネットワークセグメントに属しているため、競合は発生しません。
このようにして、Podにはクラスター内で一意のIPアドレスが割り当てられます。
PodIPとルーティングの構成
- 1番目のステップは、Podの仮想ネットワークカードに割り当てられたIPアドレスを構成する事です。
- 2番目のステップは、Podネットワークカード上のクラスターネットワークセグメントのルートを構成することです。これにより、アクセストラフィックは対応するPodネットワークカードに移動し、デフォルトルートのネットワークセグメントもこのネットワークカードに構成されます。つまり、パブリックネットワークに移動します。トラフィックもルーティングのためにこのネットワークカードに送られます。
- 最後に、PodのIPアドレスへのルートがホストマシン上で構成され、ホストマシンの反対側の端にある仮想ネットワークカードveth1をポイントします。このようにして、Podをホストマシンにルーティングすると同時に、ホストマシンでアクセスされるPodのIPアドレスを、対応するPodネットワークカードの対応するエンドにルーティングすることもできます。
2. Podをネットワークに接続する
先程の記事でPodをインターネットに接続しました。つまり、PodにIPアドレスとルーティングテーブルが割り当てられました。Pod間の通信はどのように開くのでしょうか?それは、各PodのIPアドレスにクラスター内でアクセスできます。 通常、これらのことはCNI Daemonプロセスで行います。 一般的には、このような一つのステップです。
- まず、CNIが各ノードで実行するDaemonプロセスは、クラスター内のすべてのPodのIPアドレスと、それが配置されているノードの情報を学習します。
学習方法は通常、K8s APIServerをモニターして既存のPodのIPアドレスとノードを取得することであり、新しいノードと新しいPodが作成されたときに各Daemonに通知できます。
- Podとノードに関する情報を取得したら、ネットワークを構成してつなげます。
最初に、Daemonはクラスター全体のすべてのノードへのチャネルを作成します。 ここでのチャネルは抽象的な概念であり、具体的な実装は通常、オーバーレイトンネル、Alibaba CloudのVPCルーティングテーブル、または自分のコンピュータールームのBGPルーティングを介して行われます。
2番目のステップは、すべてのPodのIPアドレスを前のステップで作成したチャネルに関連付けることです。 関連付けも抽象的な概念であり、具体的な実装は通常、Linuxルーティング、fdb転送テーブル、またはOVSフローテーブルを介して行われます。 Linuxルーティングでは、IPアドレスがルーティングされるノードを設定できます。 fdb転送テーブルは、forwarding databaseの略で、PodのIPを特定のノード(オーバーレイネットワーク)のトンネルエンドポイントに転送します。OVSフローテーブルは、PodのIPを対応するノードに転送できるOpen vSwitchによって実装されます。
この記事のまとめ
この記事の主な内容はここまでです。ここに簡単にまとめます。
- 独自の環境でK8sクラスターを構築するには、最も適切なネットワークプラグインをどのように選択すればよいですか?
- コミュニティネットワークプラグインが満足できない場合、どのようにして独自のネットワークプラグインを開発しますか?



