クラウドネイティブのCaaSプラットフォーム
高セキュリティのもとで、
圧倒的なユーザビリティで
マルチクラウドの開発・運用をサポート
- スピーディーにデプロイ
- コスト削減
- 高可用性
- 優れたスケーラビリティ
高セキュリティのもとで、
圧倒的なユーザビリティで
マルチクラウドの開発・運用をサポート




はじめに:未知の問題や未知のシステムコンポーネントのトラブルシューティングを行うことは、アフターセールスエンジニアにとって非常に楽しいことです。もちろん、これも一つの挑戦です。今日は、この記事にて、そのような問題の例を紹介します。トラブルシューティングプロセスでは、systemdやdbusなどの未知のコンポーネントを理解する必要があります。しかし、トラブルシューティングのアイデアと方法は基本的に再利用でき、それがすべての人に役立つことを願っています。
K8sトラブルシューティングシリーズの記事
1. I’m NotReady
Alibaba Cloudには、独自のKubernetesコンテナクラスター製品があります。 Kubernetesクラスター出荷数の急激な増加に伴い、オンラインユーザーはクラスターがノードのNotReadyが低確率で発生していることを時折発見していました。
私達の観察によると、この問題はほぼ毎月1人または2人の顧客によって発生します。 ノードNotReadyの後、クラスターマスターは、新しいPodの発行、ノードで実行中のPodに関するリアルタイム情報の取得など、ノードを制御する事ができなくなります。

2. Kubernetesについて知っておくべきこと
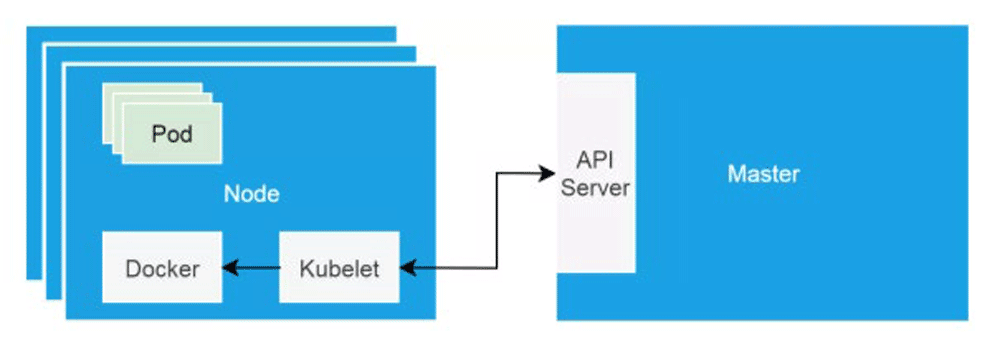
クラスターノードがNotReady状態になると、最初に行う必要があるのは、ノードで実行されているkubeletが正常かどうかを確認することです。この問題が発生したら、systemctlコマンドを使用してkubeletのステータスを確認し、systemdが管理するDaemonとして正常に実行されていることを確認してください。journalctlを使用してkubeletログを確認したところ、次のエラーが見つかりました。

3. PLEGとは何か
このエラーは明らかに、コンテナランタイムが機能しておらず、PLEGが異常であることを示しています。コンテナランタイムはdockerDaemonを参照し、KubeletはdockerDaemonを直接操作してコンテナのライフサイクルを制御します。
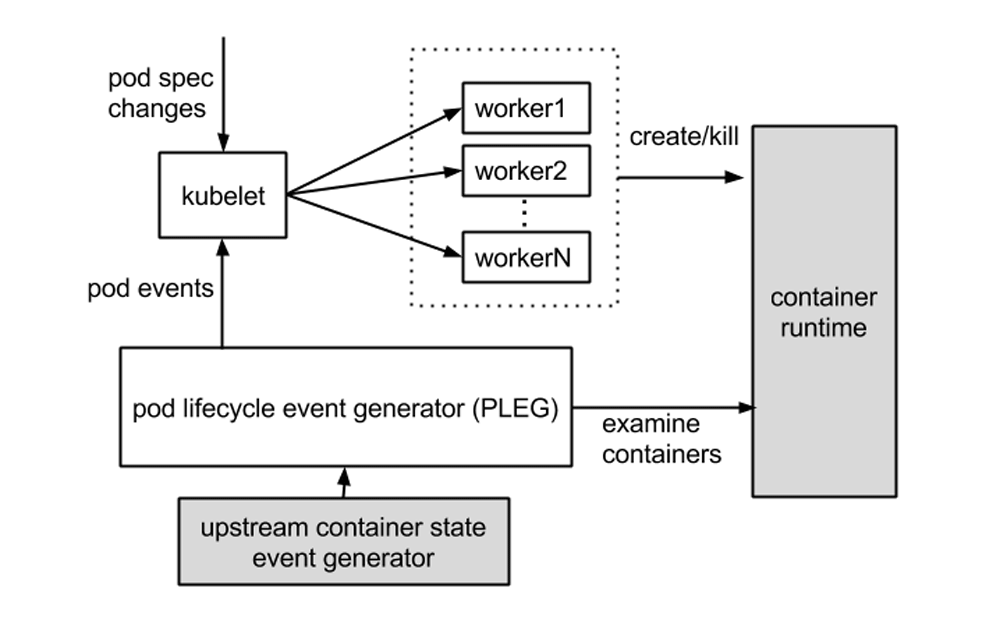
ここでのPLEGは、Podライフサイクルイベントジェネレータを指します。
PLEGは、コンテナランタイムをチェックするためにkubeletで使用されるヘルスチェックメカニズムです。これは、ポーリングを使用してkubeletによって実行された可能性があります。しかし、ポーリングにはコスト上の欠点があるため、PLEGが生まれました。 PLEGは実際にはポーリングと「中断」メカニズムの両方を使用しますが、「中断」の形式でコンテナランタイムのヘルスチェックを実装しようとします。
基本的に上記のエラーが表示されるので、コンテナランタイムに問題が発生していることを確認できます。 問題のあるノードで、dockerコマンドを使用して新しいコンテナを実行してみてください、コマンドは他に何も影響を与えません。これは、上記で報告されたエラーが正確であることを示しています。
1. Docker Daemon コールスタック分析
Alibaba CloudのKubernetesクラスターによって使用されるコンテナランタイムとして、Dockerは1.11以降、複数のコンポーネントに分割され、OCI標準に適合しました。
分割後、DockerDaemon、containerd、containerd-shim、runCが含まれます。 コンポーネントcontainerdは、クラスターノード上のコンテナのライフサイクル管理を担当し、上層のdockerDaemonにgRPCインターフェースを提供します。
の名前を確認すると、次のことがわかります。呼び出しスタックの下部は、プロセスがhttp要求を受信し、ルーティングを要求するプロセスです。上の部分は実際の処理関数に入ります。最後の処理関数は、待機状態に入ります。待機しているのはmutexインスタンスの例です。</pid><img src=)
この時点で、ContainerInspectCurrent関数の実装を確認する必要があります。最も重要なことは、この関数の最初のパラメーター、つまりmutexポインターを理解することです。 このポインターを使用してコールスタックファイル全体を検索すると、このmutexで待機しているすべてのスレッドがわかります。
同時に、以下のスレッドを見ることができます。
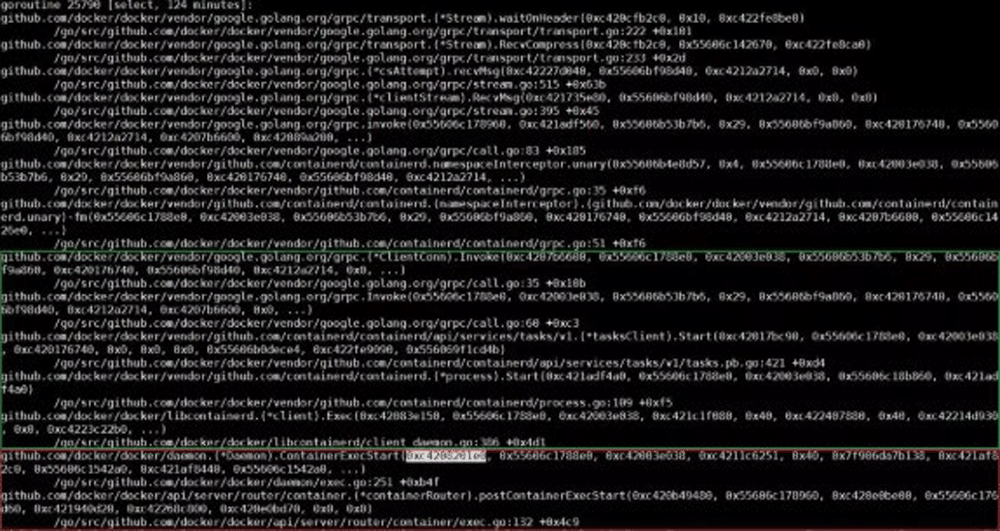
このスレッドでは、特定の要求を処理するときに、ContainerExecStart関数もmutexパラメーターを受け取ります。 ただし、ContainerExecStartはmutexを待機していないが、mutexの所有権を取得し、実行ロジックをcontainerd呼び出しにシフトした点が異なります。これについては、コードを使用して確認できます。
前述したように、containerdはgRPCを介してdockerDaemonへのインターフェースを提供します。このコールスタックの上部は、DockerDaemonがgRPCリクエストでcontainerdを呼び出しているものとまったく同じです。
2. Containerd コールスタック分析
dockerDaemonのコールスタックの出力と同様に、kill -SIGUSR1
gRPCサーバーとしてコンテナ化され、DockerDaemonからリモートリクエストを受け取った後、このリクエストを処理する新しいスレッドを作成します。gRPCの詳細については、ここではあまり注意を払う必要はありません。
このリクエストのクライアントコールスタックで、このコールのコア機能がプロセスの開始であることがわかります。containerdのコールスタックでStart、Process、およびprocess.goを検索します。以下のスレッドを簡単に見つけることができます。
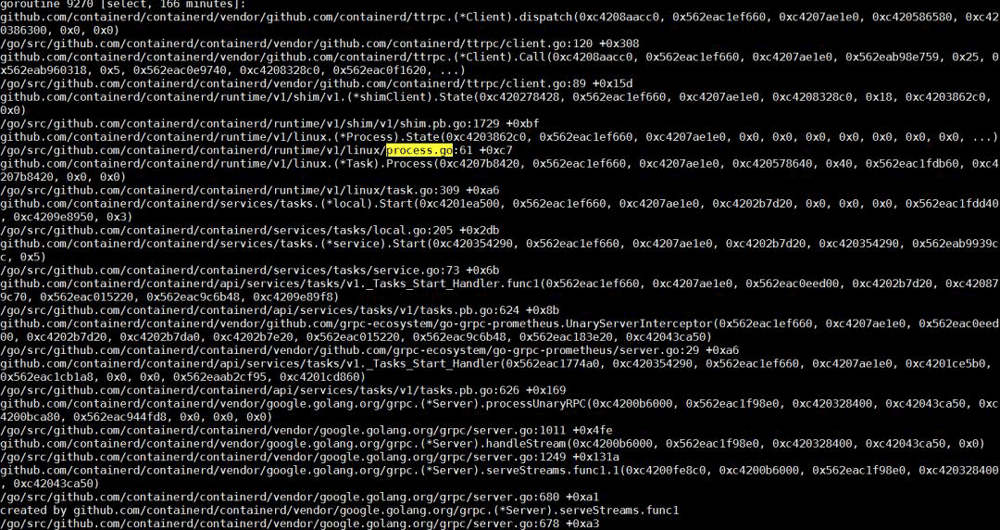
このスレッドのコアタスクは、コンテナプロセスの作成をrunCに依存することです。 コンテナが起動すると、runCプロセスが終了します。したがって、次のステップでは、runCがタスクを正常に完了したかどうかを考えます。
プロセスリストを見ると、システムにはまだ実行中の個別のrunCプロセスがあることがわかりますが、これは予期された動作ではありません。コンテナの開始とプロセスの開始には時間がかかるはずです。システムでrunCプロセスが実行されている場合、runCはコンテナを正常に開始できません。
1. RunC が Dbus をリクエストする
コンテナランタイムのrunCコマンドは、libcontainerの単純なパッケージです。このツールは、コンテナの作成や削除など、個々のコンテナを管理するために使用できます。前のセクションの終わりで、runCはコンテナを作成するタスクを完了できないことがわかりました。
私達は対応するプロセスを強制終了し、コマンドラインで同じコマンドを使用してコンテナを起動し、straceを使用してプロセス全体を追跡できます。
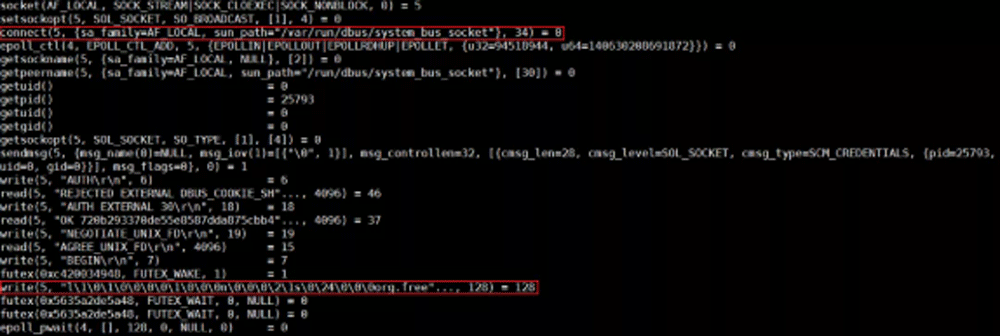
分析の結果、runCは、org.freeフィールドを使用してdbusにデータが書き込まれた場所で停止したことがわかりました。 dbusとは何か? Linuxでは、dbusはプロセス間のメッセージ通信のメカニズムです。
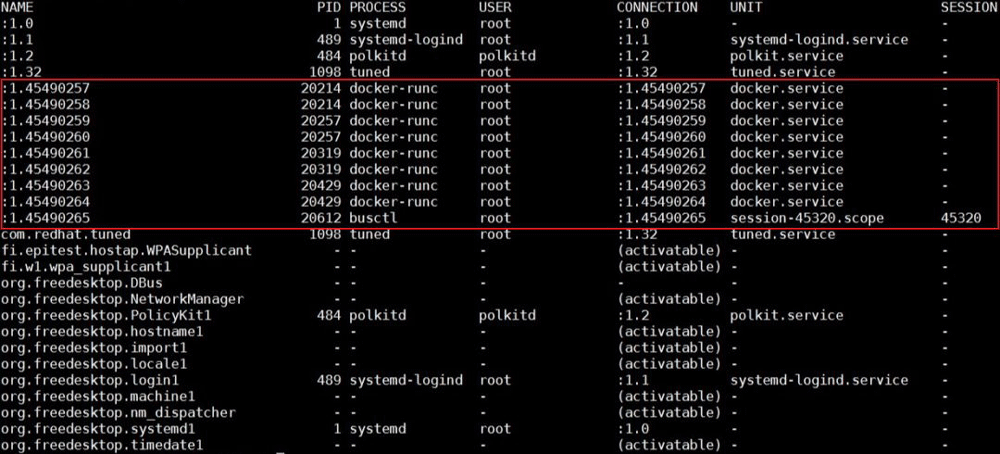
私達はbusctlコマンドを使用して、システム内のすべての既存のバスを一覧表示できます。 以下に示すように、問題が発生すると、お客様のクラスターノード名の数が非常に多いことがわかります。したがって、名前の枯渇など、dbusに関連する特定のデータ構造がこの問題を引き起こすと考えられる傾向があります。
Dbusメカニズムの実装は、dbus-daemonと呼ばれるコンポーネントに依存します。dbus関連のデータ構造が実際に使い果たされている場合、このDaemonを再起動すると、この問題が解決するはずですが、残念ながら、問題はそれほどシンプルではありません。 dbus-daemonを再起動した後、問題はまだ存在します。
上記のスクリーンショットでstraceを使用してrunCを追跡しているときに、org.freeフィールドを使用してバスにデータが書き込まれる場所でrunCがスタックしていることを述べました。 busctlによって出力されたバスリストでは、明らかにこのフィールドを持つバスがすべてsystemdによって使用されています。現時点では、systemctl daemon-reexecを使用してsystemdを再起動し、問題は解消しました。
したがって、基本的には1つの方向を推測することができ、問題はsystemdに関連している可能性があります。
Systemdは、特に私達のような開発作業を普段行っていない者にとっては、かなり複雑なコンポーネントです。基本的に、systemdのトラブルシューティングには、4つの方法を使用しました。
1. 役に立たなかった Core Dump
systemdを再起動すると問題が解決し、問題自体はdbusを使用してsystemdと通信したときにrunCが応答しなかったため、最初に確認する必要があるのは、systemdが重要なスレッドでロックされていないことです。
Core dump内のすべてのスレッドを見ると、次のスレッドのみがロックされておらず、応答するためにdbusイベントを待機しています。

2. バラバラな情報
どうしたらよいか分からず、いろいろなテストや試行をするしかありませんでした。busctl treeコマンドを使用すると、bus上のすべての公開されたインターフェースを出力できます。出力結果から、bus org.freedesktop.systemd1はインターフェースクエリ要求に応答していませんでした。
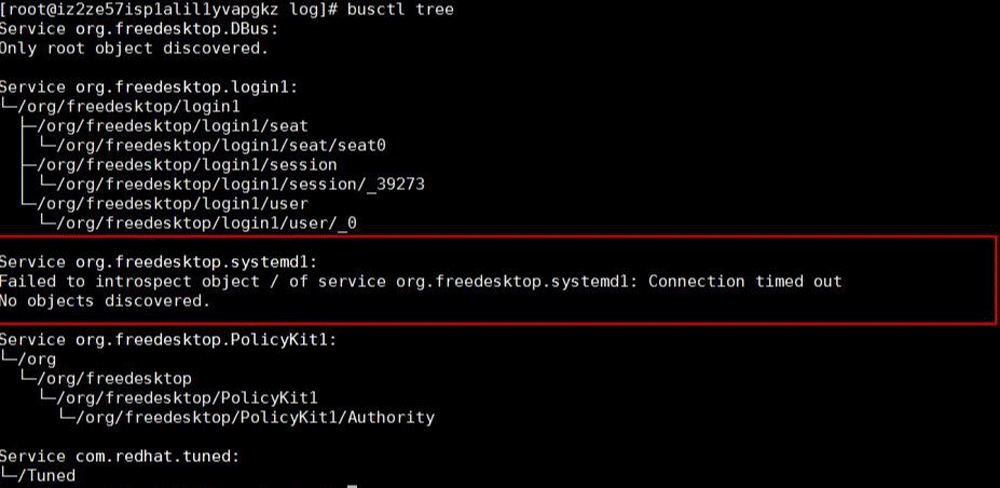
次のコマンドを使用して、org.freedesktop.systemd1で受信したすべてのリクエストを確認しました。通常のシステムでは、unitの作成と削除のメッセージが多数ありますが、問題のあるシステムでは、このbusにメッセージがまったく表示されていませんでした。
gdbus monitor --system --dest org.freedesktop.systemd1 --object-path /org/freedesktop/systemd1
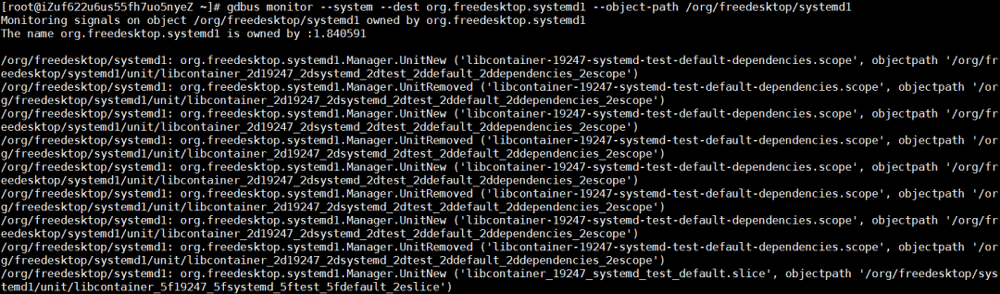
問題の前後にシステムログを分析し、runCはlibcontainer_%d_systemd_test_default.sliceテストを繰り返し実行しました。このテストは頻繁に行われますが、問題が発生した時点でこのテストは停止します。
したがって、直感でこの問題はこのテストに大きく関係している可能性があると考えました。
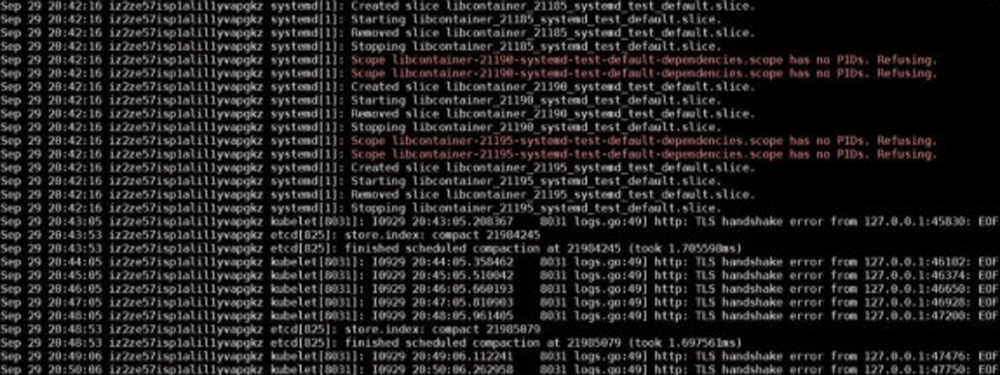
さらに、systemd-analyzeコマンドを使用してsystemdのデバッグログを開いたところ、Systemdは操作がサポートされていないというエラーがあることがわかりました。
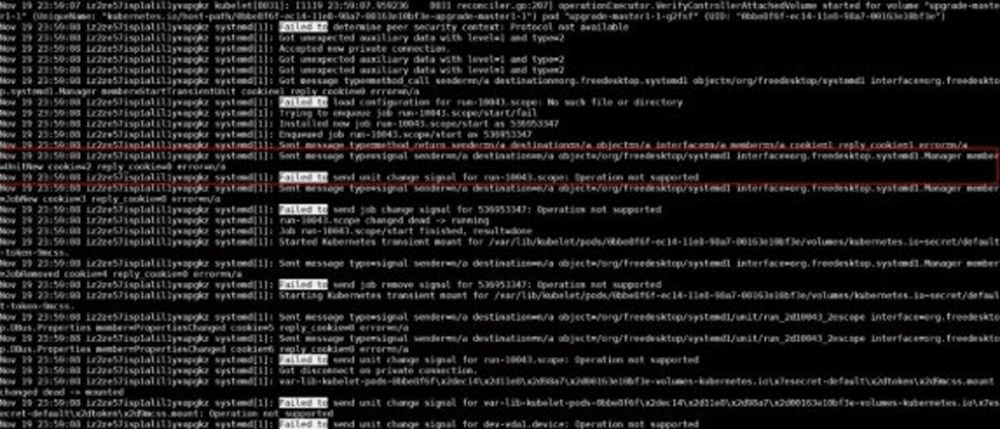
上記の断片的な知識を総合し、大まかな結論を出すことができました。 org.freedesktop.systemd1このbusは、大量のUnitの作成と削除の後、応答がありません。
そして、これらの頻繁なユニットの作成と削除のテストは、runCのチェックインが関数UseSystemdを書き換えることであり、この関数はsystemdの特定の関数が利用可能かどうかをテストするために使用されます。UseSystemdこの関数は、コンテナの作成、コンテナのパフォーマンスの表示など、多くの場所で呼び出されます。
3. コード分析報
この問題は、オンラインのすべてのKubernetesクラスターで発生し、頻度は1か月に2ケースです。問題は常に発生しており、問題が発生した後にsystemdを再起動することによってのみ処理できます。これは非常に危険です。
我々はそれぞれsystemdとrunCコミュニティにbugを提出しましたが、現実的な問題として、Alibaba Cloudのようなオンライン環境がなく、この問題を再現する可能性がほとんどないため、コミュニティを頼ってもこの問題を解決する方法がありませんでした。そのためこの問題は非常に手を焼きました。
私達は、前のセクションの最後で、問題を見つけたとき、systemdは「Operation not supported」エラーを出力する事を発見しました。このエラーレポートは問題自体とは関係がないようですが、私の直感では、これが問題の解決に最も近づく可能性があるため、最初にエラーが発生した理由を特定することにしました。
Systemdコードの量は比較的多く、このエラーを報告する場所はたくさんあります。多くのコード分析(ここでは1000語は省略されています)の結果、いくつかの疑わしい場所が見つかりました。これらの疑わしい場所で、次に行うことは待機することでした。3週間後にオンライン上のクラスターで最終的に問題を再現しました。
4. Live Debugging
お客様に許可を求めた後、systemdデバッグシンボルをダウンロードし、gdbをsystemdにマウントし、疑わしい関数の下にブレークポイントを設定し、実行を続行しました。多くの検証の結果、systemdが最終的にsd_bus_message_seal関数のEOPNOTSUPPエラーを踏んでいることがわかりました。

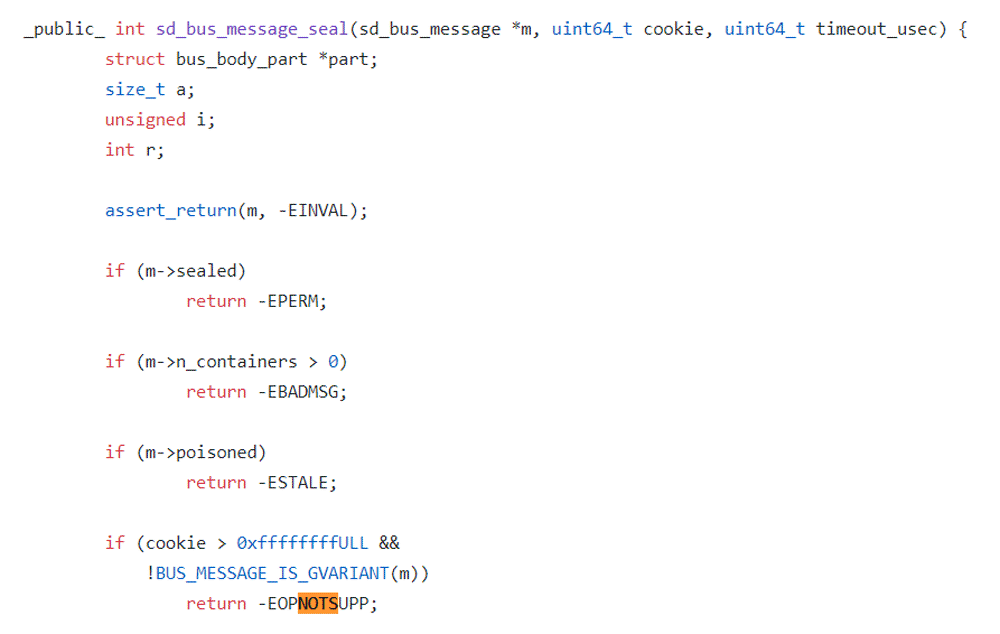
このエラーの理由は、systemdが変数cookieを使用して、処理するすべてのdbusメッセージを追跡するためです。新しいメッセージをカプセル化するたびに、systemdは最初にCookie値を1つ増やし、次にCookie値を新しいメッセージにコピーします。
gdbを使用してdbus-> cookieの値を出力していますが、この値が0xffffffffを超えていることがはっきりとわかります。そのため、systemdが多数のメッセージをカプセル化した後、32ビットのCookie値がオーバーフローし、新しいメッセージをカプセル化できないという問題があるようです。

さらに、通常のシステムでは、gdbを使用してbus-> cookieの値を0xffffffffに近い値に変更し、cookieがオーバーフローするとすぐに問題が発生することを確認します。これにより、結論がわかりました。
5. どのようにしてクラスターノードNotReadyが問題を引き起こしていると判断したか
まず、問題のあるノードにgdbとsystemd debuginfoをインストールし、次にgdb / usr / lib / systemd / systemd 1コマンドを使用してgdbをsystemdにアタッチし、関数sd_bus_sendにブレークポイントを設定して、実行を続行する必要があります。
systemdがブレークポイントを踏んだ後、p / x bus-> cookieを使用して対応するCookieの値を確認します。この値が0xffffffffを超えると、Cookieがオーバーフローし、必然的にノードNotReadyの問題が発生します。確認後、quitを使用してデバッガーをデタッチできます。
この問題の修正は簡単ではありませんでした。 1つの理由は、systemdが同じcookie変数を使用してdbus1およびdbus2と互換性があることです。
もう1つの理由は、オーバーフローの問題を解決するためにCookieを単純に再入力できないことです。これにより、systemdが同じCookieを使用して異なるメッセージをカプセル化する可能性があるため、結果は惨憺たるものになります。
最後の修正は、32ビットCookieを使用してdbus1とdbus2の両方の状況を処理することです。同時に、Cookieが0xfffffffに到達した後の次のCookieは0x80000000を返し、最上位ビットはCookieがすでにオーバーフロー状態であることを示します。 Cookieがこの状態にあることを確認する場合、Cookieの競合を回避するために、次のCookieが他のメッセージによって使用されているかどうかを確認する必要があります。
この問題の根本的な原因は間違いなくsystemdですが、runCの関数UseSystemdはあまり美しい方法を使用せずにsystemdの関数をテストしています。この機能は、コンテナのライフサイクル管理プロセス全体で頻繁にトリガーされ、この低確率の問題の発生を可能にしました。
systemdの修正はRed Hatに受け入れられましたが、近い将来、systemdをアップグレードすることでこの問題を根本的に解決できることが期待されています。